![]()
หากพูดถึงเทคโนโลยีด้านเสียงของ Sony ซึ่งเป็นบริษัทยักษ์ใหญ่ด้านระบบเสียง นอกจากแอมป์ดิจิทัล S-Master ที่เราได้เคยเขียนถึงไปแล้ว ก็ยังมีเทคโนโลยีที่ช่วยปรับปรุงคุณภาพเสียงอย่าง DSEE หรือ Digital Sound Enchancement Engine ที่ได้ถูกใช้งานกับอุปกรณ์หลากหลายอย่างของบริษัททั้งเครื่องเสียง, โทรทัศน์, สมาร์ทโฟน หรือแม้กระทั่งหูฟังไร้สาย
วันนี้เราจะมาทำความรู้จักเทคโนโลยี DSEE ของ Sony กันให้มากขึ้นครับ
Why sound needs enhancement?
ในการสื่อสารด้วยเสียงหรือกระจายเสียงไม่ว่าจะเป็นรูปแบบแอนะล็อกหรือดิจิทัลนั้น มีโจทย์สำคัญที่ต้องแก้คือการทำอย่างไรให้สัญญาณถูกส่งไปยังปลายทางได้อย่างครบถ้วนโดยใช้ย่านความถี่ที่มีอยู่จำกัดได้อย่างมีประสิทธิภาพ ด้วยเหตุนี้จึงทำให้เกิดการคิดค้นเทคนิควิธีการมอดูเลตและบีบอัดสัญญาณต่าง ๆ ขึ้นมา เพื่อให้สามารถส่งสารไปยังปลายทางได้อย่างครบถ้วนโดยใช้ย่านความถี่น้อยที่สุด
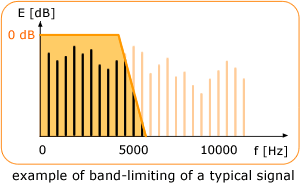
ตัวอย่างของสัญญาณเสียงที่จำกัดความถี่ไว้ ที่มา : Coding Technologies
อย่างไรก็ตามคุณภาพเสียงที่ได้จากการส่งสัญญาณด้วยวิธีต่าง ๆ ในอดีตนั้นมีคุณภาพต่ำ เพราะการออกแบบให้ความสำคัญกับโจทย์ข้างต้นก่อน เช่น การส่งกระจายเสียงผ่านระบบวิทยุ AM และ FM นั้นสามารถส่งสัญญาณความถี่ได้เสียงเพียง 5 kHz และ 15 kHz จากช่วงความถี่เสียงที่มนุษย์สามารถได้ยินได้ (20 Hz – 20 kHz) เพื่อให้มีจำนวนช่องใช้งานได้เพียงพอตามย่านความถี่ที่เปิดให้ใช้งานได้ หรือการบีบอัดเสียงในรูปแบบดิจิทัลที่มักใช้เทคนิค Perceptual Coding เพื่อลดปริมาณข้อมูลในการบีบอัดโดยการจำกัดช่วงความถี่เสียงจากหลักการได้ยินของมนุษย์ แต่ก็ทำให้ข้อมูลเสียงในช่วงย่านความถี่สูงนั้นหายไปจนกระทบกับคุณภาพเสียง เช่น ในการบีบอัดแบบ MP3 ที่ Bitrate 64 kHz นั้นจะมีช่วงความถี่ของสัญญาณเสียงเพียงประมาณ 10 kHz เท่านั้น ทำให้เสียงฟังดูทึบ ขาดความชัดเจนไป
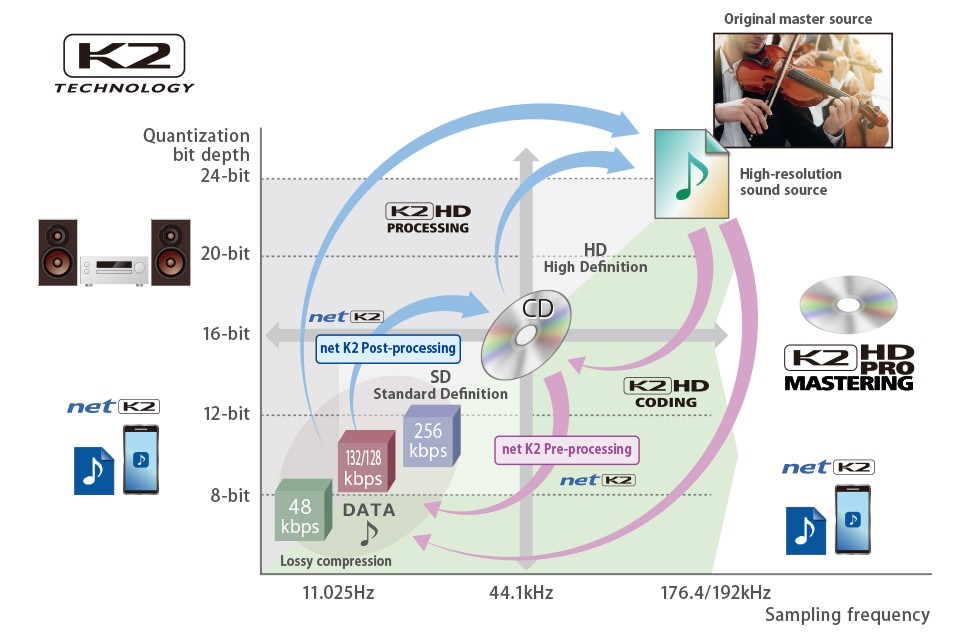
ตัวอย่างการนำ K2 Technology ไปใช้งาน ที่มา : JVCKENWOOD
ในส่วนของการฟังเพลง ก่อนหน้าที่จะถึงยุคการบีบอัดไฟล์เสียงแบบ MP3 ก็มีคนที่มองว่ามาตรฐาน Audio CD ที่นิยมใช้งานอยู่นั้นยังไม่สามารถถ่ายทอดเสียงได้อย่างสมจริงได้ ซึ่งส่วนหนึ่งเกิดจากช่วงความถี่ของเสียงสูงสุดของมาตรฐานที่ 22.05 kHz ซึ่งถึงแม้จะเกินจากความถี่เสียงสูงสุดที่มนุษย์สามารถได้ยินได้ แต่ก็ไม่เพียงพอในการถ่ายทอดความถี่ฮาร์โมนิกที่เครื่องดนตรีสามารถสร้างขึ้นได้ จนเป็นที่มาของเทคโนโลยีอย่าง K2 Technology ที่ร่วมกันพัฒนาโดย Victor Company of Japan (JVC) และ Victor Studio (Victor Entertainment) ในปี 1987
เมื่อมาถึงยุครุ่งเรืองของการบีบอัดไฟล์เพลงแบบ MP3 ที่เหล่าผู้ผลิตเครื่องเสียงหลายค่ายได้หาวิธีต่าง ๆ เพื่อปรับปรุงคุณภาพเสียงที่เกิดการสูญเสียจากการเข้ารหัส MP3 จนทำให้เกิดเทคโนโลยีอย่าง DSEE ของ Sony, K2HD Processing ของ JVCKENWOOD, M-DAX ของ Marantz, Crystallizer ของ Creative, HFFx ของ Oxford Digital (Sony Pro-Audio Lab เดิม) และอื่น ๆ อีกหลายเจ้า ซึ่งแต่ละเจ้าก็เลือกใช้เทคนิคหลากหลายอย่างในการปรับปรุงคุณภาพเสียง
แต่มีอยู่เทคนิคหนึ่งที่เป็นเทคนิคสำคัญที่พลิกวงการด้านการเข้ารหัสสัญญาณ และถูกใช้เป็นพื้นฐานในการบีบอัดสัญญาณเสียงที่เราใช้งานอยูกันทุกวันนี้ นั่นคือ Spectral Band Replication (SBR) ที่ถูกคิดค้นขึ้นโดยบริษัท Coding Technologies จากสวีเดนในปี 1997 (บริษัทถูก Dolby ซื้อไปในปี 2007)
Spectral Band Replication (SBR)
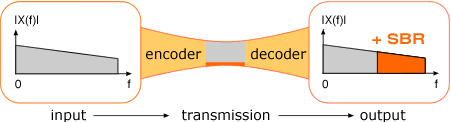
ที่มา : Coding Technologies
Spectral Band Replication เป็นเทคนิคการเข้ารหัสข้อมูลเสียงซึ่งถูกออกแบบมาเพื่อใช้งานร่วมกับการเข้ารหัสเสียงอื่นที่มีอยู่แล้ว SBR อาศัยหลักการที่ว่าลักษณะสัญญาณในช่วงความถี่สูงนั้นสัมพันธ์กับลักษณะสัญญาณในช่วงความถี่ต่ำเป็นอย่างมาก เราจึงสามารถอนุมานได้ว่าสัญญาณที่มีอนุกรมฮาร์โมนิกในช่วงก่อนความถี่จุดตัดนั้น จะมีอนุกรมฮาร์โมนิกเดียวกันในช่วงความถี่สูงด้วย ถึงแม้ว่าอาจจะไม่เหมือนกับอนุกรมในช่วงความถี่เก่าเสียทีเดียว และในย่านเสียงความถี่ต่ำมีสัญญาณที่มีลักษณะคล้ายนอยส์ ในย่านความถี่สูงก็จะมีสัญญาณนอยส์ดังกล่าวด้วยเช่นกัน
นั่นหมายความว่า เราสามารถที่จะเข้ารหัสข้อมูลเสียงเฉพาะในย่านความถี่ต่ำ แล้วค่อยไปสร้างข้อมูลเสียงในย่านความถี่สูงขึ้นมาจากลักษณะของสัญญาณเสียงในย่านความถี่ต่ำตอนถอดรหัสข้อมูลแทน ช่วยให้เราสามารถส่งสัญญาณเสียงได้ครบถ้วนในทุกย่านความถี่ โดยเข้ารหัสบีบอัดข้อมูลที่ Bitrate ต่ำได้

ที่มา : Bandwidth extension of audio signals by spectral band replication โดย Per Ekstrand
ขั้นตอนการทำงานของ SBR นั้นจะทำงานก่อนตัวเข้ารหัสหลัก (Core Encoder) และทำงานหลังตัวถอดรหัสหลัก (Core Decoder) โดยก่อนเข้ารหัส SBR Encoder จะสร้าง SBR Data ซึ่งมีขนาดเล็กมากจากสัญญาณที่เข้ามา เพื่อให้ SBR Decoder ใช้เป็นแนวทางในการสร้างสัญญาณความถี่สูงกลับได้อย่างแม่นยำ และส่งสัญญาณเสียงที่ครึ่งหนึ่งของความถี่อัตราสุ่มสัญญาณไปยังตัวเข้ารหัสหลักเพื่อทำการเข้ารหัสข้อมูลตามปกติ
ส่วนฝั่งถอดรหัสนั้น หลังจากที่ข้อมูลสัญญาณเสียงถูกถอดรหัสแล้ว SBR Decoder จะใช้ข้อมูล SBR Data เพื่อสร้างสัญญาณย่านความถี่สูงกลับขึ้นมา โดยหากสัญญาณเสียงใดไม่สามารถใช้สัญญาณย่านความถี่ต่ำมาอ้างอิงในการสร้างสัญญาณกลับได้ ก็จะใช้ Sinusoidal Regenerator และ Noise Generator สร้างสัญญาณขึ้นมาใหม่ตามข้อมูลจาก SBR Data แล้วนำไปรวมกับข้อมูลเสียงที่ถอดรหัสไว้เพื่อนำไปเล่นกลับขึ้นมา
ด้วยเทคนิคนี้ทำให้คุณภาพเสียงที่ได้จากการบีบอัดข้อมูลที่ Bitrate ต่ำนั้นมีคุณภาพเสียงที่ดีขึ้นมาก สามารถทำคะแนนการทดสอบ MUSHRA ได้มากกว่า 80% ซึ่งถือว่าทำคะแนนได้อย่างยอดเยี่ยม และได้ถูกนำไปใช้งานในการเข้ารหัสอย่าง aacPlus และ mp3Pro รวมทั้งถูกทาง MPEG นำไปใช้เป็นเทคนิคพื้นฐานของการเข้ารหัสแบบ HE-AAC ทำให้อุปกรณ์พกพาต่าง ๆ สามารถรับส่งสัญญาณเสียงแบบไร้สายด้วย Bit Rate ที่ต่ำ ช่วยให้ประหยัดพื้นที่จัดเก็บและค่าใช้จ่ายในการรับส่งข้อมูล

ที่มา : IEEE
จากผลงานดังกล่าวทำให้ผู้ประดิษฐ์เทคนิค SBR ทั้งสามคน ได้แก่ Martin Dietz, Lars Liljeryd และ Kristofer Kjörling ได้รับรางวัล IEEE Masaru Ibuka Consumer Electronics Award ในปี 2013 และหลักการของเทคนิค SBR ก็ถูกนำไปประยุกต์ใช้ในงานปรับปรุงคุณภาพเสียงอื่น ๆ อีก
ในตอนหน้า เราจะไปดูรายละเอียดการพัฒนาเทคโนโลยี DSEE ของ Sony กันว่าเป็นอย่างไร เพื่อน ๆ ที่สนใจก็อย่าลืมติดตามกันนะครับ
Pingback: มาทำความรู้จัก DSEE เทคโนโลยีปรับปรุงคุณภาพเสียงจาก Sony กันเถอะ ตอนที่ 2 | RE.V –>